Com a adição de novas funcionalidades de dia para dia e com os preços em constante queda, muitas empresas estão neste momento a avaliar a migração dos seus sistemas locais para o Microsoft Azure.
Dentro da estratégia de migração, grande parte dos sistemas empresariais (senão a totalidade) serão migrados para o serviço “Azure Virtual Machines” e a razão é simples: É a forma mais rápida e fácil de migrar para a Cloud. Muitas organizações já têm os seus sistemas virtualizados in-house, pelo que a transição é facilitada e pode inclusive ser feita sem grande transtorno ou downtime. A Microsoft assegura a transição através de soluções hibridas em que o Azure pode ser visto como uma extensão do datacenter local o que permite migrar por fases ou até optar por “apenas” implementar novos projetos nesta nova plataforma.
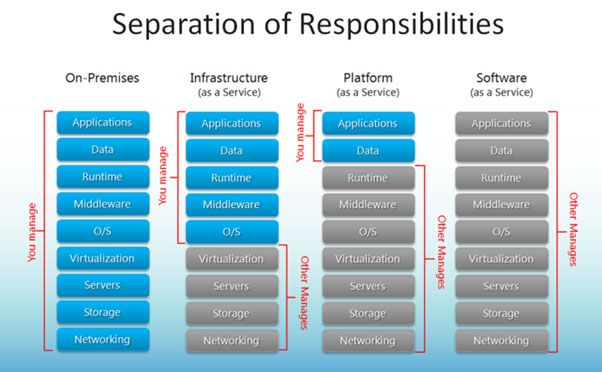
O Microsoft Azure foi inicialmente pensado para oferecer apenas soluções Platform as a Service (PaaS), estas soluções são altamente escaláveis e elásticas e retiram do cliente qualquer preocupação com os sistemas. O Azure SQL Database por exemplo oferece ao cliente um serviço de base de dados SQL em que apenas temos de nos preocupar com os dados propriamente ditos. Tudo o resto está assegurado para que o nosso sistema corra 24/7, temas como instalação de updates, manutenção do servidor, SQL Mirroring e backups são automaticamente garantidos pela plataforma que está disponível 99,99% do tempo.
Este tipo de disponibilidade nos serviços PaaS é conseguido, com uma arquitetura de hardware e software que foi desenhada a pensar não só numa escala massiva, mas também tendo conta as inevitáveis falhas. Tudo é pensado tendo em conta que o hardware ou determinada instância logica vai falhar.
Numa arquitetura desenhada tendo em conta a falha ou crash, nada falha. Na prática isto significa que neste modelo todo o software foi desenvolvido e configurado para não “confiar” no hardware.
No Azure é considerado como ponto de falha uma rack de servidores (fault domain). Quer isto dizer que a plataforma tolera a falha de uma rack inteira mantendo o serviço que o cliente subscreveu operacional, mesmo que o sistema do cliente resida na rack que falhou. Isto é conseguido pois a plataforma assegura que existem outras instâncias da mesma aplicação a serem executadas noutras racks vizinhas ou até noutro datacenter. Estas instâncias estão programadas para reagir normalmente a este tipo de falhas para que o cliente final não sinta qualquer downtime devido a uma falha completa de um dos membros do grupo ou a distúrbios decorrentes de tarefas de manutenção.
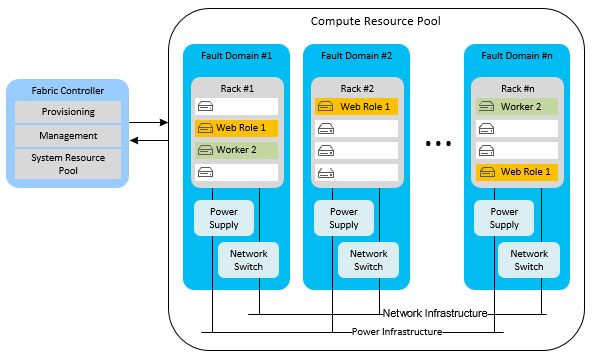
É pela razão acima mencionada que os servidores físicos utilizados no Azure não têm componentes redundantes. O conceito de tolerância a falhas de um simples servidor neste caso não se aplica. A rack ou está toda funcional ou então é considerada faulted.
Podemos de certa forma dizer que, em termos de disponibilidade, o Azure vê uma rack inteira da mesma forma que a maioria de nós vê um servidor no datacenter.
Tudo isto faz perfeito sentido para os serviços PaaS em que tudo é gerido pela Microsoft e nós apenas lá colocamos os dados e interagimos com os mesmos. No Azure SQL Database por exemplo, não nos é possível alterar contas de serviço, instalar updates, reiniciar o sistema operativo, ter acesso ao disco rígido do servidor ou muito menos alterar as configurações de alta disponibilidade do SQL. Estas são tarefas a cargo da plataforma e que a mesma efetua tendo em conta a disponibilidade contínua do serviço.
Quando utilizamos o serviço Infrastructure as a Service (IaaS) – Azure Virtual Machines, os SLAs e modo operacional diferem das soluções PaaS:
- Virtual Machines e Virtual network:
A Microsoft garante que todas as máquinas virtuais que tenham duas ou mais instancias implementadas no mesmo availability set uma conetividade de 99,95% do tempo.
- Armazenamento:
A Microsoft garante que em 99,99% do tempo os dados estarão acessíveis.
É Importante ter em consideração que para beneficiar da disponibilidade anunciada temos de aprovisionar uma segunda máquina virtual (VM) no mesmo “Availability Set” de forma a redundar a primeira. Caso não existam pelo menos duas VMs para o serviço que queremos disponibilizar a Microsoft não garante qualquer nível de serviço para a componente em causa.

A configuração aplicacional para o conjunto de duas ou mais máquinas virtuais está a cargo do cliente, sendo o mesmo o único responsável por garantir que o serviço que as mesmas disponibilizam sobrevive a este tipo de falhas (reboots e unexpected shutdowns). O que a Microsoft pode garantir é que pelo menos uma das VMs do conjunto está disponível em 99,95% do tempo e que nunca estarão indisponíveis em simultâneo.
A razão para a ausência de SLA para soluções com uma única VM é simples: Ao aprovisionarmos uma máquina virtual para um determinado serviço, a mesma vai ser colocada em execução num qualquer servidor que faz parte de um “fault domain”. Caso o mesmo falhe ou esteja em falha iminente, vai haver interrupção do serviço até que a máquina virtual seja movida para um servidor diferente através de um processo chamado de “healing”.
Adicionalmente a Microsoft necessita de efetuar ações de manutenção aos servidores físicos (updates, upgrades, etc), manutenção esta que pode exigir um ou mais reboots aos mesmos. Durante estas ações a VM pode ficar indisponível por longos períodos de tempo (existem relatos de períodos superiores a 2 horas).
Por diversas conversas que tenho com Clientes, verifico que este facto causa na maioria das vezes surpresa, não só pelo custo que se apresenta maior que o estimado devido à duplicação de alguns recursos mas também e principalmente porque grande parte das aplicações empresariais não são possíveis de colocar num modelo de alta disponibilidade com múltiplos servidores a assegurar o serviço. Existem também casos em que a complexidade de configurar, gerir e monitorizar uma solução de alta disponibilidade dentro de duas ou mais Virtual Machines tem um custo proibitivo de suportar.
A verdade é que até ao presente, para evitar a complexidade e dar robustez a aplicações que não foram concebidas a pensar na falha do hardware, as Empresas têm efetuado investimentos em clusters de virtualização com sistemas de “live migration” e em servidores e storage totalmente redundantes para evitar que os mesmos falhem e os serviços fiquem indisponíveis. Este é um paradigma diferente do que o Microsoft Azure segue (design for failure) e no qual assentam a maioria das aplicações de nova geração. Esta discrepância por vezes causa uma expetativa incorreta nos Clientes empresariais sobre as soluções Cloud de grande escala.
Uma outra questão que por vezes causa surpresa, está relacionada com o backup: No serviço Azure Virtual Machines, temos a garantia de que os nossos dados estão triplicados no datacenter e que dificilmente serão perdidos devido a uma falha. No entanto, se pretendermos recuperar dados apagados inadvertidamente ou de uma data anterior, o backup terá de ser assegurado pelo cliente que pode subscrever um serviço adicional no próprio Azure ou utilizar uma solução de terceiros ou com scripts.
Apesar de muito facilitada a transição, não devemos descurar o planeamento e o impacto da passagem dos sistemas para a plataforma da Microsoft. Existem questões de arquitetura da maior importância que devem ser avaliadas com um especialista para assegurar uma migração com sucesso e dentro das expetativas de cada organização.
Artigo escrito por Nuno Carvalho, CTO da Knowledge Inside (www.knowledgeinside.pt)














{kind=link}
Comentários